OpenAI Realtime Voice x Reasoning Hackathon
Overview
In March 2025, I participated in the OpenAI Realtime Voice x Reasoning Hackathon, a high-intensity, 19-hour competition hosted over two days and sponsored by OpenAI, with support from Nebius, Kamiwaza AI, and Neon. This hackathon challenged participants to push the limits of what’s possible using OpenAI’s latest realtime and reasoning models, working alongside industry mentors, developers, and design engineers to create AI-powered experiences that respond at the speed of thought.
The Tech
The event centered on building cutting-edge voice and reasoning applications using OpenAI’s newest tools: the Realtime API and the o1 reasoning model. These tools allow for low-latency multimodal interactions, including live voice-to-voice conversations, real-time transcription, and complex multi-step reasoning. As AI transitions from demo-stage novelty to production-grade reliability, the hackathon asked participants to imagine what new architectures and user experiences might look like for instantaneous AI interaction.
Context
Before diving into our project, it’s worth noting the powerful capabilities of the tools at our disposal:
The OpenAI Realtime API enables real-time speech-to-speech conversational experiences, transcription, speech generation, function calling, and multimodal understanding via models like GPT-4o and GPT-4o mini.
OpenAI Reasoning Models (like o3, o4-mini, and o1) are fine-tuned for internal chain-of-thought reasoning, making them ideal for problem-solving, planning, and complex logic. Larger models like o1 offer greater capabilities at a higher cost and latency, while smaller versions prioritize speed and efficiency.

Judging Criteria
Projects were judged across four dimensions:
Running Code - Teams had to produce real, working code—not just concepts or mockups.
Innovation & Creativity - Emphasis on pushing boundaries and introducing novel ideas.
Real-world Impact - Solutions were expected to demonstrate the potential to solve real and meaningful problems.
Theme - Evaluation of how closely the project aligned with the challenge to build “cutting-edge AI apps.”
(Scoring definitions from the judging rubric are included in the image below.)

Meet the Judges
-

Ilan Bigio
Developer Experience – OpenAI
-

Diamond Bishop
Director of Engineering/AI – Datadog
-

Lior Cole
Founder – ARI
-

Ben Fornefeld
Design Engineer – Self
-

Chris Hua
Founder – Tincans
-

Jonathan Murray
Organizer – AI Tinkerers
-

Nicole Ripka
Investment Team – Betaworks
-

Matthew Wallace
Co-Founder & CTO – Kamiwaza
-

Andrew Yeung
CEO – Fibe
Overview: Building a Realtime AI Interview Coach
After an intense round of brainstorming, our team gravitated toward a concept that felt both deeply human and technically ambitious: an AI-powered interview coach capable of engaging in natural, realtime voice conversations while offering intelligent, context-aware feedback.
We envisioned a coach that doesn’t just spit out generic tips—but actually listens, reasons, and responds like a seasoned hiring manager. Using OpenAI’s Realtime API, the coach could interact with users through fluid, lifelike dialogue: asking follow-up questions, encouraging elaboration, or even adjusting tone based on user hesitancy or overconfidence. For example:
If a user nervously answered “I guess I’d say communication is my strength…”, the coach could respond:
“I noticed some hesitation—can you give me a clear example of when strong communication helped you succeed?”If a user rambled off-topic, it might gently steer them back:
“Thanks for sharing! Let’s bring it back to the leadership experience you mentioned—how did that impact your team?”
But it wasn’t just about voice. We also leveraged OpenAI’s reasoning models to analyze three key data sources:
The user’s resume
The job description of the role they were preparing for
A body of interviewing best practices and industry norms
By combining these inputs, the coach could tailor its questions and feedback in ways that felt personalized and practical. It might challenge the user on a vague accomplishment, suggest STAR-format improvements, or highlight areas where their experience didn’t align with the job's expectations—just like a human coach would.

Speak Up
Our solution was SpeakUp — an AI-powered speech coach that makes communication improvement easy, efficient, and measurable. Users could practice mock interviews, rehearse presentations, or simply speak on a topic of their choice, while SpeakUp delivered real-time insights on clarity, pacing, articulation, and delivery. The experience felt more like talking to a supportive coach than using a piece of software.
Meet the Team
-

Brandy Li, MBA
Project Manager
-

Justin Nathaniel
Lead Designer
-

Seva Oparin
Senior ML Engineer
-

Vladislav Kuznetsov
Backend Engineer
-

Alex Lazarev
Frontend Developer
Research: Laying the Groundwork Under Pressure
With only 19 hours to build, test, and present a fully functional AI application, the clock was a constant presence. Every decision had to serve not just our vision—but our velocity.
Early on, I recognized that rushing into wireframes without a strategic understanding of the landscape and tools would slow us down later. So I carved out time (2 hours) to focus on two critical research tracks that would directly inform our product’s direction and UX design:
1. Competitive Landscape: What Already Exists in the Coaching Market?
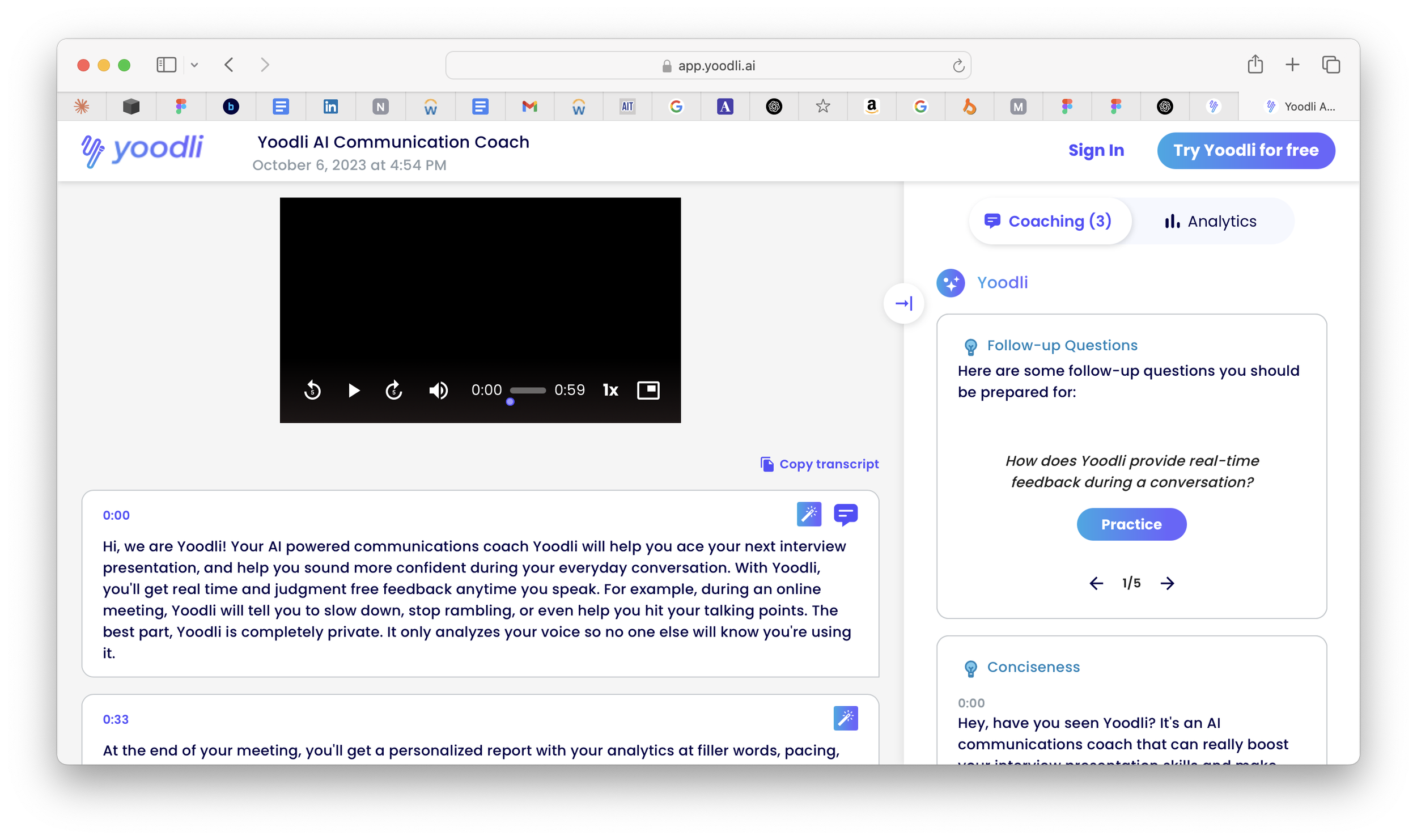
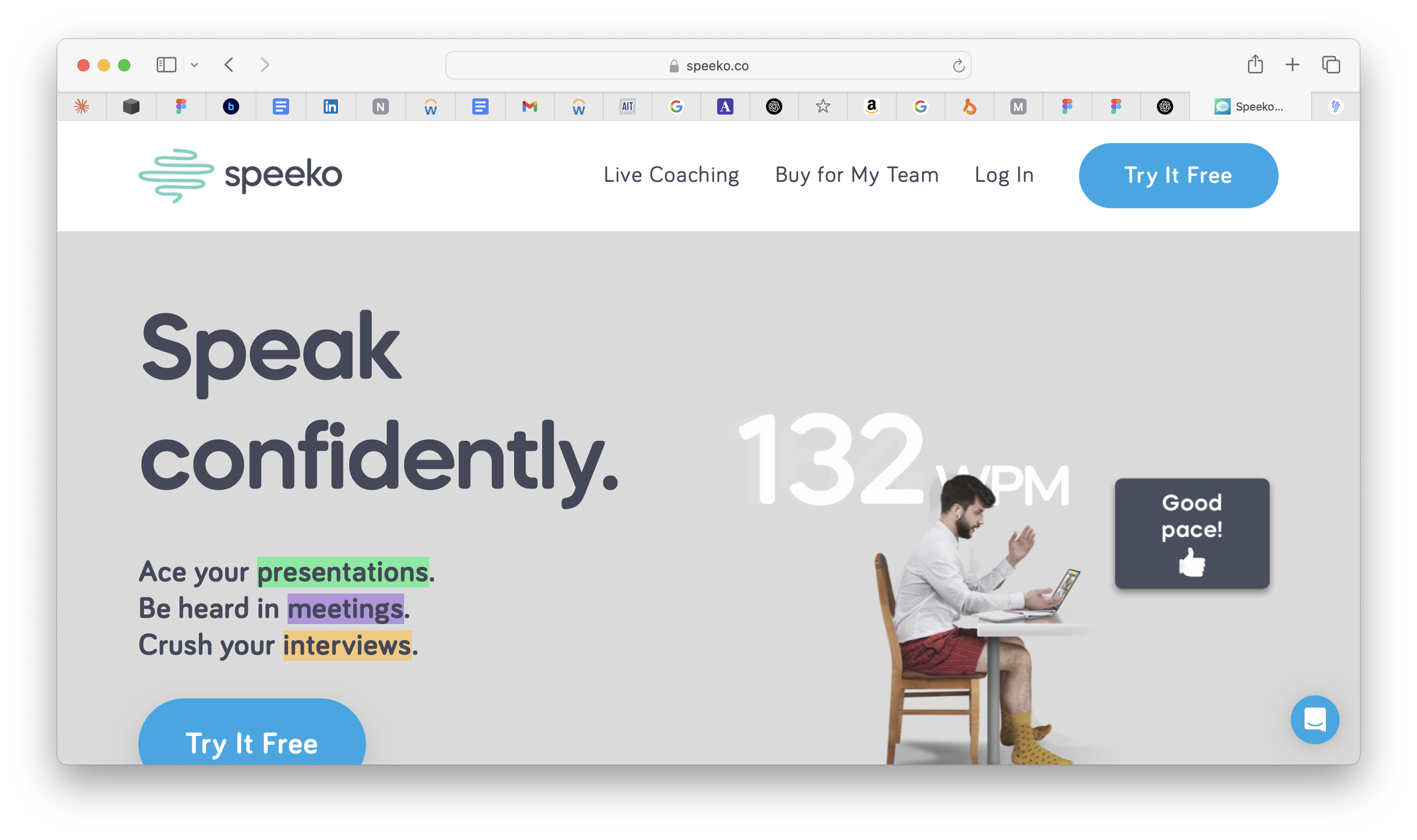
To position SpeakUp in a meaningful way, I analyzed several competitors in the voice and communication coaching space. This included apps like Yoodli, Speeko, and Tempo. I looked closely at:
Brand positioning – How do they speak to users? Do they feel clinical, playful, or supportive?
Feature analysis – What kind of feedback do they offer (e.g., filler word detection, tone analysis, pacing metrics)?
UX strengths & gaps – Where did they create friction, and where did they shine?
This brand and feature audit helped us identify opportunities for differentiation: notably, none of the major players fully integrated real-time, two-way voice interactions that adapt based on user tone and resume context.
2. Technical Capabilities: Understanding Realtime + Reasoning Constraints
I also dove into OpenAI’s documentation, community forums, and spoke with staff onsite to better understand the tools at our disposal—particularly the Realtime API and the o1 reasoning model. I wanted to surface:
Best practices for integrating low-latency audio input/output
Known limitations like latency thresholds, turn-taking timing, or token output pacing
Design affordances—how the model’s reasoning depth might shape coaching interactions (e.g., should we avoid compound prompts, or allow it to summarize user patterns?)
This early technical grounding was crucial. It helped us avoid unnecessary iteration later and ensured our design choices were built around the model’s strengths rather than working against its limitations.




Key Findings from Competitive Analysis
TLDR:
None fully combine realtime voice + deep reasoning: We didn’t find any product that leverages both low-latency audio interaction and high-level reasoning in tandem.
Yoodli is the most comprehensive, focusing on sales, leadership, and professional communication training with AI-powered roleplays.
Speeko is ideal for public speakers and individuals looking to refine their voice, confidence, and presentation skills.
Tempo is best for real-time pacing adjustments during presentations and multi-platform compatibility with video conferencing tools.
Voice feedback is mostly one-way: Tools like Speeko and Yoodli offer insights or scores after the user speaks, but lack real-time, conversational engagement.
Personalization is shallow: Most apps provide generic tips that aren’t grounded in context like job roles or resumes.
UI often favors data over dialogue: Many products overwhelm users with charts, scores, and metrics—missing the chance to feel like a supportive human coach.
Gamification is underused: There’s a missed opportunity to motivate users through goal-setting, streaks, or progress tracking.
Accessibility and inclusivity are inconsistent: Few apps account for accents, neurodiversity, or speech impairments in a meaningful way.
None fully combine realtime voice + deep reasoning: We didn’t find any product that leverages both low-latency audio interaction and high-level reasoning in tandem.
Project Approach
By hour four of the hackathon, my anxiety was rising.
We had a solid concept, promising research, and a clear sense of potential—but no designs yet. The engineers had been doing their own technical discovery, and while progress was being made in parallel, I knew that without a clear UX direction soon, we’d risk losing precious time.
We paused, regrouped, and each member of the team shared their findings. This brief but vital sync allowed us to revalidate our concept against the judging criteria and ensure our solution wasn’t just ambitious—it was aligned with what mattered:
Real-Time Voice Interaction
Our coach would offer immediate, actionable feedback on delivery—listening in real-time to help users course-correct mid-sentence.Advanced Reasoning
The model would analyze context and speech structure, providing intelligent, personalized suggestions based on what the user was trying to convey.Innovation & Creativity
SpeakUp wasn’t just a timer or feedback form—it was a coach, always present, always learning from you.Real-World Impact
Whether for students, professionals, or anyone seeking to level up their speaking skills, SpeakUp had the potential to offer real confidence through real practice.
Translating Research Into Features
Armed with competitive insights, we moved quickly to define what SpeakUp must do to stand out:
1. Real-Time Speech Analysis
Speech-to-Text Conversion: Live transcription as the user speaks.
Pacing & Pausing Detection: Monitor speed and detect irregular rhythm.
Tone & Volume Analysis: Ensure clarity and modulation across delivery.
Filler Word Detection: Spot “um,” “uh,” and other speech crutches.
Clarity & Pronunciation Checks: Flag moments where the message might be getting lost.
2. Context-Aware Feedback
Real-Time Alerts: Subtle visual or auditory cues to help users adjust on the fly.
Adaptive Suggestions: Feedback based on user speech + resume + job role.
Multi-Turn Interaction: Allow users to ask for more feedback mid-session.
3. Post-Presentation Analysis
Summary Dashboard: Metrics on pacing, tone, clarity, and filler usage.
Performance Heatmaps: Visual breakdowns of strengths and weak spots.
Personalized Recommendations: Insights based on repeated use.
4. UX Enhancements
Gamification Elements: Scores, badges, and progress tracking.
Integration Potential: Slide decks or video conferencing integrations in the future.
Project Structure Breakdown
Once features were prioritized, we immediately outlined our execution plan to move forward without chaos:
1. Planning & Requirements
Define MVP Goals: Prioritize realtime feedback + voice interaction.
Select Tech Stack:
Speech Recognition: OpenAI Whisper
Voice & Reasoning: GPT-4o + o1
Frontend: React
Backend: Python with Flask
Realtime Protocol: WebSockets
2. System Architecture & Design
Voice Input Module: Stream audio to backend in real time.
Processing Engine:
Transcribe voice input
Analyze for pace, tone, clarity, filler usage
Feedback Engine:
Deliver real-time audio or visual feedback
Generate post-session analysis
Dashboard/UI:
Present metrics and insights in a clean, engaging interface
Data Flow Diagram:
From microphone → AI processing → real-time suggestions → session recap
Despite the tight timeline, this structure gave us the confidence to move quickly with clarity. The design work began immediately afterward, fueled by urgency but now backed by aligned vision and technical grounding.
Design
With our architecture and features locked in, we immediately shifted into design. Time was tight, and we knew our engineers needed something now—not next hour.
We made a deliberate choice to start with low-fidelity wireframes, sketched quickly by hand. Paper was perfect: fast to produce, easy to iterate, and most importantly, immediately usable. As soon as one sketch was complete, it was handed off to engineering so they could start building the skeleton of the app while we continued designing the rest of the flow.
Design Goals
Even at the wireframe stage, our designs were guided by a few key principles:
Speed of use – No friction, no unnecessary delay. The user should be able to speak within seconds of onboarding.
Real-time visibility – Users needed to see feedback as it happened, without distraction or delay.
Clarity over complexity – Data and metrics are only useful if they’re instantly understood. We avoided overloading the UI with charts.
Coach, not critic – Visual tone mattered. Feedback should feel supportive, not punitive.
Wireframe Priorities
We broke our low-fidelity designs into four core experiences:
First Run Experience (FRE)
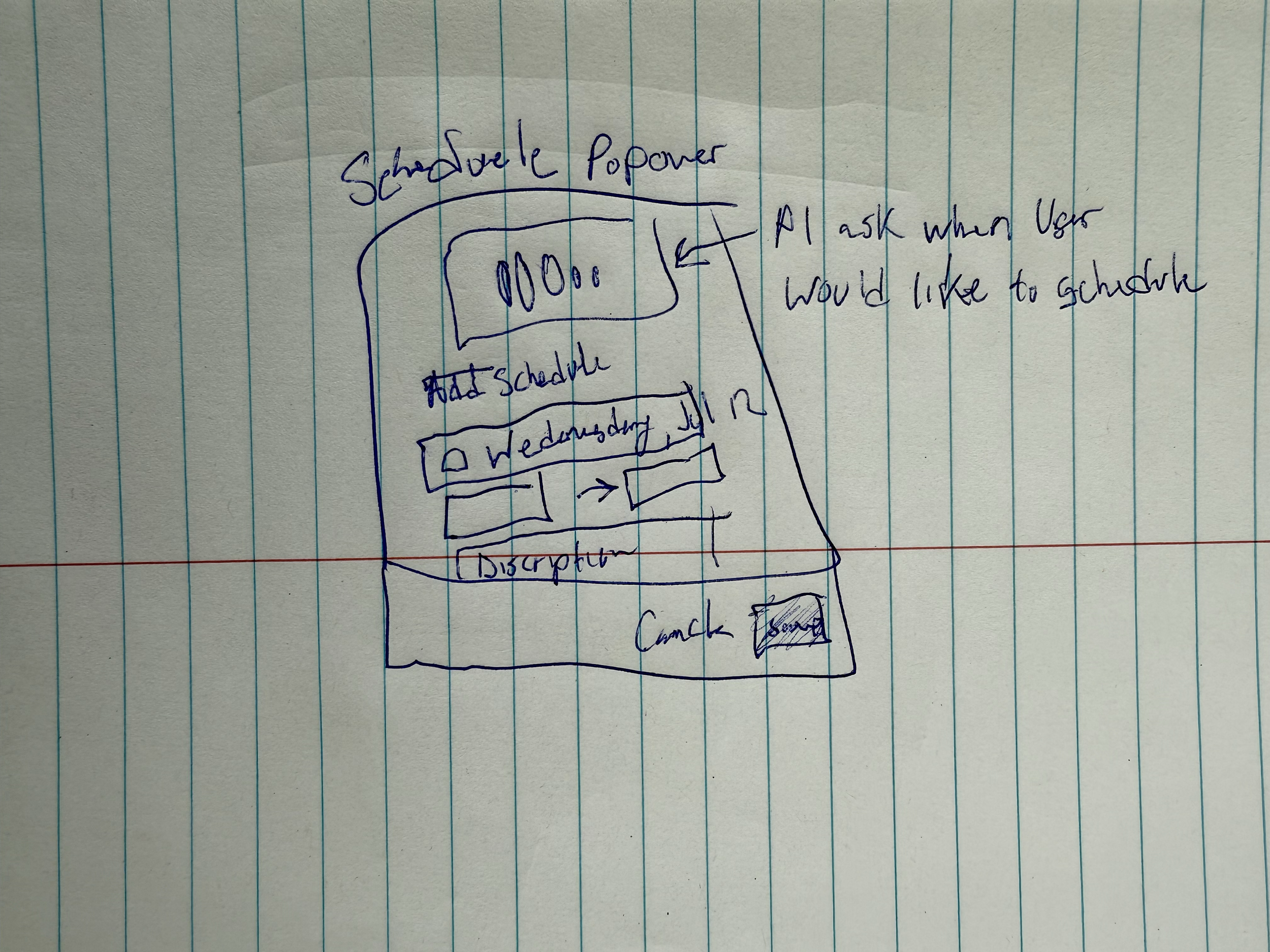
A lightweight onboarding flow where users could upload or input their resume and target job description, priming the model for personalized feedback. This helped ensure the coaching aligned with each user’s goals.Speaking Interface
A minimalist screen where the user could start speaking, with real-time visual indicators for tone, pace, and filler word detection.Live Feedback Panel
Non-intrusive tips and alerts that appeared contextually—e.g., “Slow down slightly,” or “Try rephrasing that last point.”Post-Session Dashboard
A simple summary screen with metrics, visualizations (like filler word frequency or pacing heatmaps), and one or two tailored improvement tips.
By prioritizing only the most essential interactions, we gave engineers just enough structure to start building fast.
High-Fidelity Wireframes
As development progressed, it became clear that low-fidelity sketches—while great for speed—weren’t enough. Our engineers needed more detail to properly structure the frontend layout and interface logic. To bridge that gap, we quickly transitioned into creating high-fidelity wireframes that would bring SpeakUp’s core experience into sharper focus.
These screens helped anchor the app’s visual layout, clarify UI expectations, and reinforce standard design patterns for natural language processing (NLP)-driven products—particularly around input/output pacing, feedback placement, and conversational rhythm.
Designing for Interaction, Not Just Aesthetics
This stage of design wasn't about making things pretty. It was about enabling the engineers to build smarter and faster, and making sure the experience felt intuitive for the user.
We imagined a visual representation of the real-time voice feedback, featuring an animated voice “entity” that would respond with subtle pulsing or waveform-like motion. This gave users a focal point for conversation, making the AI feel more alive, less abstract.
The UI followed clean, familiar patterns—like floating action buttons, toggle panels, and iconography—to ensure users wouldn’t feel lost.
We introduced the first elements of brand identity:
A cool-toned signature color, chosen based on gaps and saturation trends from our competitive analysis.
Early work on a logo, with an upturned arrow forming the “U” in SpeakUp—a nod to growth, vocal power, and a distinctive, trademark-able visual hook.
Designing for Risk Mitigation
While the front-end and back-end engineers were making steady progress, they began encountering unexpected complexity while integrating the Realtime API. Latency handling, token streaming, and voice synthesis outputs were proving difficult to implement in such a short window.
That’s when we made a strategic call: if something broke, we still needed to show our vision working.
We decided to create a fully interactive Figma prototype on our second day of the hackathon as a failsafe. This prototype mirrored the intended user flow from onboarding to real-time coaching and post-session insights. If we couldn't get a working voice interaction in time, we wouldn’t meet the “running code” requirement.
The high-fidelity prototype became more than a design tool—it became our insurance policy.